Launch series: ← Part 1: the WiseTech turn · ← Part 2: the optimist turn · ← Part 3: a forwarder's call · Part 4 (you're here)
This is the last post in the launch series. Parts 1-3 set up the case. This is what we did about it.
When I talk to founders of other companies going through a similar moment, the question I hear most is: "do you let AI do everything, or do you draw lines?"
We draw lines. Two of them. This post is about both.
The short version: AI is allowed at the edge and not in the core. Experimental features are built as embeds first, as full modules second. Everything else — the reorg, the new website, this blog, the freemium tools — is downstream of those two rules.
The first rule: AI at the edge, not in the core
Every freight platform has two kinds of things inside it. The first kind are records that money and cargo depend on: accounting entries, shipment records, customs filings, billing, audit logs. The whole Operate layer of our platform. If one of those records is wrong, a forwarder can't just press undo. Carriers invoice the wrong amount, shippers get the wrong paperwork, customs authorities get the wrong filing, and unwinding it takes weeks.
The second kind is everything else. Document extraction. Status drafts. Quotation assembly. Natural-language analytics. Workflow agents that compress multi-step operational sequences. The places where AI can produce 80-90% of the output fast, and a human can correct what's off before anything durable happens.
Sometime early this year we wrote down a rule that we'd actually been operating on by instinct for months:
AI lives at the Adaptive Edge. AI does not live in the Stable Core.
An AI can propose a journal entry; a deterministic accounting engine is the only thing that can commit one. An AI can draft a customs declaration; a country-specific deterministic adapter is the only thing that can file it. An AI can read an arrival notice; a human accepts the extracted fields before anything books into the system of record.
That rule does a specific thing that's underrated: it lets us be aggressive at the Edge without ever putting the Core at risk. Most of our competitors will spend 2026-2027 picking between "AI everywhere" (and occasionally shipping outages the market remembers for years) and "AI nowhere" (and falling visibly behind on productivity). We don't pick. We ship AI fast at the Edge. We stay conservative in the Core. Both at once.
I'm keeping this short here on purpose — the full treatment of Stable Core / AI Adaptive Edge, including the incidents that shaped the rule and where the line is still fuzzy, is its own post later in this series. What matters for the shape of the company is: that line exists, it's written down, it's enforced in the architecture, not just in review.
The second rule: embed first, full module second
The first rule was about where AI is allowed to act. The second is about how we build experimental features at all.
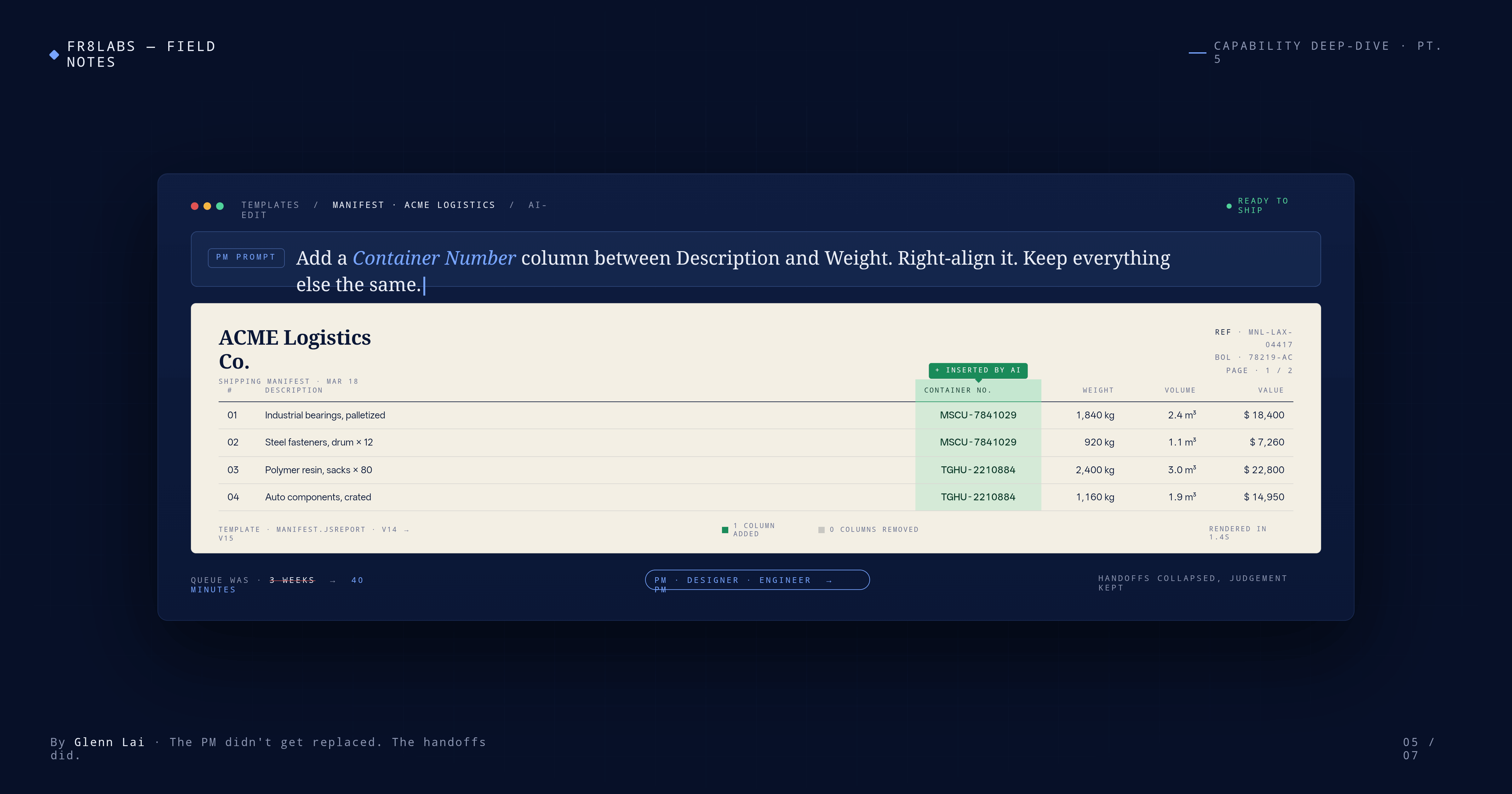
Earlier this year, I was personally building our Notification Hub module — the layer that coordinates how the platform talks to customers, carriers, and the forwarder's team across email, WhatsApp, portals, and a few other surfaces. I was working on it alongside the team, in evenings and quiet afternoons, partly because I wanted to see if I could ship something grade-A without pulling an engineer off the roadmap.
I could. But the more interesting discovery was how I'd built it.
Instead of designing a full new module with its own screens and navigation, I embedded the capability directly into surfaces our users already spent their day inside — a thin interactive layer inside an existing workflow, not a separate destination. The tradeoff was deliberate. Lighter UX, but faster iteration — ship, watch real usage, revise, ship again.
That pattern became a rule for the whole team:
For new features that aren't 100% proven, we build them as thin embeds first. Graduate to a full module only when usage earns it.
Every new experimental module in our pipeline now starts this way. The doctrine saves us from the classic trap where you build a full new module with its own nav, its own onboarding, its own screens, its own documentation — and then find out six months later that only 12% of customers actually use it.
What this rule rhymes with, structurally, is the first rule. Both are "draw a line between experimental and durable." The AI rule draws it between the Edge and the Core. The module rule draws it between a thin embed and a full module. Same discipline, two different layers. Experiments live cheap; proven patterns graduate.
How we staff against the rules
Rules are only useful if a team is actually structured around them. We made an internal change earlier this year that most external observers missed: we now run external innovation and internal innovation as two distinct engineering tracks.
The external track continues to ship customer-facing AI products — the capabilities you see on our product page, DocuSense and its peers. The internal track is the muscle that builds the tools, patterns, and platform inside Fr8Labs that let the rest of the company operate at a multiple. The embed-first pattern came out of that work. So did the AI-assisted template editor that turned a three-week engineering backlog for print-out customizations into a three-day self-serve queue. So did the internal infrastructure that makes this blog possible — and a few other things you haven't seen yet.
The split matters because it lets both tracks go faster. External product work isn't bottlenecked on whether an internal automation should promote to a customer feature. Internal work isn't bottlenecked on whether an external AI product should be built as a module or an embed. The rules the team operates under are clearer because the work is structured around them.
What this produced
The two rules plus the reorg are why this year has shipped more than the two years before it combined, with no increase in engineering headcount. Some of the visible outputs:
-
The website you are reading. An agency spent roughly four months on the previous version we never launched — structurally 90% done, content 0%, stalled through a combination of disruptions including one person's paternity leave. I killed it and rebuilt this site with AI in about five working days of focused work, spread over a few weeks of calendar time because of travel and meetings. A more personal post on that is coming in a later entry of the series.
-
Why Fr8Labs. A page built specifically to pre-filter our sales conversations. I use it on live demos now — it sets expectations for what a Fr8Labs customer relationship looks like and filters out prospects we'd disappoint, before anyone spends time they'll regret. It's the single most useful sales tool we've built this year, and it was built in an afternoon.
-
This blog itself. The CMS, the AI editor, the publishing pipeline, the scheduling feature — all of it shipped in a focused sprint over the past week. This post was drafted in that system, edited in it, and published through it. If you're reading this on fr8labs.co/blog, you're looking at one of the embed-first pattern's outputs.
-
Our freemium tool line. The first is Stow8, a public cargo planner forwarders can use for free. More coming. Each one of these is a marketing motion — they do more to qualify a forwarder lead than any demo request form we've ever run.
-
The AI-assisted template editor, the internal KB context pipeline, the AI Analytics surface, the document extraction pipeline. Each is a translator-layer capability that customers will see in product over the next quarter. Each got shipped faster because of the embed-first rule.
None of these are finished work. They are outputs of a new muscle, and the muscle is the important thing. The specific features it produces this year will be different from the specific features it produces next year. The muscle stays.
What I'd ask you to take away
Three questions worth asking any vendor in freight-tech over the next twelve months:
- Where does your AI commit records to the core database? The right answer is it doesn't. If the answer is anything else, follow up.
- How do you decide when an experimental feature becomes a first-class product capability? A vendor with a process has thought about this. A vendor without one will still be figuring it out while you're live.
- Who owns internal innovation separately from external innovation? If the answer is "the same team," ask how they're choosing between the two. There's a real cost to not choosing.
The short version of everything I've written in this series: the old shape of software is dying; the new shape is bigger than the old shape ever was; customers are already asking for the new shape in their own words; and the companies that draw discipline lines — between Edge and Core, between embed and module, between external innovation and internal — are the ones who'll actually ship it at the speed the market is now moving.
That is the company we're building. It's the argument behind this website, behind the philosophy page, behind the four posts in this series, and behind every sprint on our roadmap this year. I expect it to evolve. I don't expect the shape to change.
— Glenn
This is the final post in the launch series. Return to the blog →, or start over with Part 1 →.